
票据、相关分析。相关分析主要是通过探究各个变量之间的相关系数,来探究各个变量之间的相关程度。
这个在Eview中是如何实现的?首先打开造影剂s,选中三个变量,右击用左打开,然后单击vo,里面有个斜方叉分析。去掉斜方叉分析的四选框,选择下面这个关系,然后单击p值,选中这两个框然后单击确定,便能够得到三个变量之间的相关系数。
那么这个可以把这个图截取到后面,需要的比如说截取到word里面或取或者截取到excel或者截取到ppt里面,在截取的时候大家可以选中这个表格,然后右击复制,单击确定。同时,比如说想要粘贴到文档里面,然后打开一个文档,右击粘贴就行。但是这种情况粘贴过来是以图片的形式进行粘贴的。
但是大家在写论文的时候会出现很多论文要求不能出现格式,图片样式,如此需要把它转化成图表样式。怎么转化成图表样式?可以就是粘贴的时候选择选择性粘贴里面有一个带格式的文本,单击确定。粘贴了一个内容,但是这个文本是以表格形式存在的,并且可以进行编辑,这种情况就符合论文的要求,大家了解一下就行。
如果有需要的同学可以进行操作,再返回ppt,返回ppt在做出来皮尔逊相关系数的结果以后,接下来就开始对它进行分析了。
从这个表中能够看出变量 y和变量xe之间的相关系数是0.45784,那么它下面的数值是什么?下面这个数值是对相关系数进行了统计值的检验,相关统计检验以后对应的p值,这个p值还是跟0.05比,若小于0.05就表明上面0.457四这个同志关系数是能够很好的代表整体的。
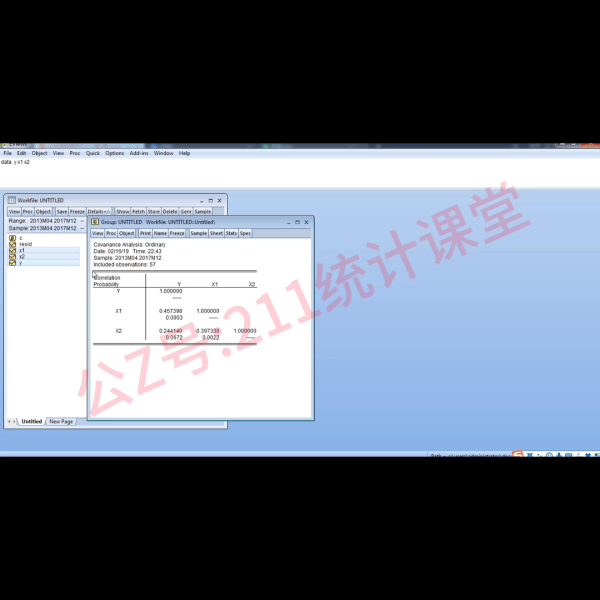
反之大于0.05就表明相关系数是不能很好的代表总体的。也就是说比如y与x二的相关系数是0.2/4幺,但是它的 p值是0.72是大于0.05的,就说明在百分之五的显著性水平向下填写,y与x之间的相关系数0.2/4幺并不能很好的反应总体。这也就是对这这个周期性相关系数的分析,至于具体的分析就是按照这一段话大家可以按照右侧的这段话来进行分析,此处我就不给大家念了。接下来进行 EviX相关分析完成。以后我们需要通过进一步通过一元或者多元线性回归模型来探究变两个自变量,x一和x二对变量y到底有多大的影响程度。
接下来开始讲解二点四的内容一元或者多元进行股规分析。一元或多元现金回馈分析在 Evi中是如何实现的?首先再接着打开 DN1,关掉刚才做的相关分析的结果,然后重新选择三选择三个变量。选择完以后用按方程打开,按方程打开。记住此处不是按组打开了按方程打开,打开以后便会出现呼吸方程的对话框。

在这个对话框中大家可以看看到上面有四个变量,其中有三个是刚才选所选的变量 y c、x二还有个c,表示的是洁具项。
接下来在下面的方法选择,因为回归一般选用的是默认的最小二乘法,也就是现在的ls方法,此时不变,依然用最小二乘法来进行估计,单击确定,便能够看到估计出来的回归分析结果。如果想把结果复制到word 里面,也是按照刚才的方式进行复制就可以。再接着回到ppt来对回归分析结果来进行分析,大家可以看左侧的这个表,其中有五列数据,第一列是容量,第二二列是变量的估计系数,第三列是变量的标志物,第四列是变量经过替统计值检验得到的统计值,第五列是替统计值检验对应的p值。
该怎么分析?以变量x一为例,大家可以看到变量x一对应的估计系数是五点零九乘以十的负七次方,对应的标准物是一点五六乘以十的负七次方。经过T检验以后,对应的统计值是三点二五四八,而t值对应的p值是零点零零二零,这个p值是小于零点零五的。
也就是说在百分之五的显著性水平下,电量x、e对音电量y的影响是非非常显著的。这就是对x一的分析,同样的对x二的分析能够看出变量x二的估计系数是零点零零零一对应的标准物是零点零零零二,而对应的p值是零点五六三六p值是零点五六三六p值相应的p值是零点五七五四,这个p值是远远大于零点零五的。也就是说百分之五的显著性水平下变量x二对因变量 y的影响并不是特别的显著。这就是对它的数值上的解释。

在这要注意的一点是,这个替统句值是怎么得出来的?是由估计系数除以它的标准物,得出来。比如说x一的剔除统计值三点二五四八,就等于五点零九乘以十的负七次方,除以一点五六乘以十的负七次方。得到的。这个大家要注意一下。
这两个变量的经济意义是怎么解释的?首先解释变量 x一,它的经济意义是在保持另外一个变量不变的情况下,也就是说在保持x二不变的情况下,x一每增加一个单位,y平均增加五点零九乘以十的夫妻四方的单位,也就是说他的夫妻系数值。而对x二的经济意义解释就是,在保持x一不变的情况下,x二每增加一个单位,y平均增加零点零零零一个单位。
回归分析,下面的洁具项,c这个是不参与经济意义分析的,这个大家注意一下就行。在经济意义分析的时候尤其要注意,我在右侧标黄的这几个字眼是必须要写到的,以保持经济意义分析的严谨性。
就说,要在进行多元线性合格分析的时候必须在写在保持另外一个变量不变的情况下分析这个变量,并且是xe每增加一个单位平均增加,而不是说y直接增加,这两个意义是不一样的,大家要注意。

在对单个变量分析完了以后,对所有对模型进行分析。如何对模型进行分析?主要观看下面的米和优度,也就是r以及修正后的女朋友,对也就是修正后的阿芳,以及下面的f值以及f值对应的p值,主要看这四个值。
很多同学会有疑问,为什么会有修正后的阿芳这个说法?因为r方有一个特点,就是r方与样本量的多少是存在正向的关系的。也就是说,如果这个数据电量选取的不是很恰当,但是样本量足够大,那么它的r方也是会很大的。这种情况下就不能很精确的反应变量之间的影响程度。
为了剔除这种样本量的影响,提出了修正后的阿芳这个概念。修正后的阿芳在一定程度上是剔除了样本量的因素影响的,就相对而言更能精确的反面变量之间的影响程度。修正后的r方是零点一八四七,它是与一进行比较离一离得比较远。可将模型模型拟合的比较一般,并不是那么的好。

一般情况下,大于在零点九左右零点八左右,可以说是模型拟合的比较好的。而这个模型估计对应的f统计值是七点三四零,而这个f统计值对应的p值是零点零零幺五小于零点零五。可见,在百分之五的显著性水平下自变量整体对应变量的影响是显著的。在这要注意,f值探究的是所有的自变量对应变量的影响而不是单个自变量对一个人的影响。
还有的一点就是,若像x一和x二中所有的自变量中只要有一个是显著的,这个f统计值肯定是显著的,若完全都不显著,这个f统计值也是肯定不显著的。这就是对其进行线性回归分析后的结果。在进行线性回归分析完以后,要在此基础上对这个自变量,以及其得到的反差项进行相关的检验,以判断其是否违背了相关的假设检测。
本文来自投稿,不代表闪电博客-科普知识-常识技巧网立场,如若转载,请注明出处http://www.tuosiweiyingxiao.cn/post/404832.html
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。如有侵权联系删除邮箱1922629339@qq.com,我们将按你的要求删除









